AWS覚書
- 1 そうだ AWS しよう
- 2 子曰く、「牛刀割鶏」
- 3 給食のおばちゃんPro、或いは、ある自衛隊員の矜持
- 4 ここまでの整理
- 5 プロジェクト「炊具一合」始動!
- 5.1 API仕様
- 5.2 最初の実装
- 5.3 AWSで動かす
- 5.4 一度は見たいオーロラ
- 5.5 見れなかったオーロラ、聖母様お助けください
- 5.6 MariaDB用にプログラムを改変
- 5.7 はじめチョロチョロ、なかパッパ
- 5.7.1 S3やってみた
- 5.7.2 Python Script on EC2
- 5.7.3 バイバイ。マリア
- 5.7.4 [閑話休題] ゼロから作る Deep Learnibg
- 5.7.5 [閑話休題] NumPyはクセがすごい、、、というほどでもなかった
- 5.7.6 はじめまして、アテナさん
- 5.7.7 尊師グルのスティッキー・フィンガーズ!
- 5.7.8 ラムだっちゃ!
- 5.7.9 モンティだっちゃ!
- 5.7.10 Androidで位置情報の送信
- 5.7.11 Androidで位置情報の記録
1 そうだ AWS しよう
Amazonのクラウドについて勉強しようかと思い立つ。コンピュータについてテクニカルな事柄を勉強する場合、実際に何らかのシステム(アプリケーション)を作成しながら覚えていくのが良い。というわけで、まずはアマゾンのクラウドサーバとストレージを利用して、位置情報データベースを作成してみようと思う。仕様は驚くほど簡単だ。
- 位置情報をサーバにアップロードする。
- アップロードされた位置情報は適宜ダウンロードできる。
2 子曰く、「牛刀割鶏」
早速、心の中のもう一人の自己が批判する。
「あん?馬鹿じゃね。ファイル保存で間に合う。百歩譲ってもSQLiteで十分。」
「なんで『鶏を割くのに牛刀を用いん』だよ。」
、、、等々と。その通りである。どう考えても大げさである。大掛かりな道具立ては、はっきりって余計に面倒くさい。しかしである。勉強とはこういうものである。これは挑戦なのである。簡単なことを敢えて難しい環境の中でやり遂げる。それでこそ、新しい知識が身につこうと言うものだ。そう、「牛刀式勉強法」である。
3 給食のおばちゃんPro、或いは、ある自衛隊員の矜持
牛刀割鶏。カッコつけて言ったものの。2000年以上も前の故事である。近頃のチビッコ達は牛刀など見たこともあるまい。いい年したオジさんである私も見たことない。これはいけない。意味が通じないではないか。しかも、発想がネガティブである。「大げさだから止めておけ」である。大げさだからこそ、敢えてやりたい。そういった大胆不敵さがない。よろしい。ならば、現代的、ポジティブな例えに置き換えてみよう。「例え」は何より大事である。複雑な事象でも身近なものに置き換えることにより、より理解が深まる(実際には深まったような気になる)のである。さて、チビッコ達も給食用の大釜は見たことがあろう。なんとあの大釜、一度に50合(5升)ものコメが炊けるらしいのである。そして、給食のおばちゃんに問うてみよう。「大釜で一合炊きは出来ますか」と。殆どのおばちゃんは尻込みして言うだろう。「そんなの、無理無理」と。しかしながら、プロフェッショナルなおばちゃんであれば答える。「私になら出来る」、、、と。英雄である。大釜と言う扱いづらい炊具で一合のコメを炊くのは神の所作に等しい。それでも、その至難の業をこなす技術力を持ってこそ、本当に美味しいおコメが炊けるというものではなかろうか。決まった。無駄でも敢えてやってみて己の限界を高める。それに見合った新しい標語は、「炊具一合」である。炊具一合の精神をもってこそ、日本の将来を担う世代の食は育まれ、一合炊きの技術を持ってこそ、ひいては、災害救助、国防までもが達成されるのである。なぜなら、この技術を必要としているのは、まさに自衛隊であり、炊具1号の活躍で日本国は成立しているからである。以上を踏まえて、今回のプロジェクトの名称を「炊具一合」とする。
4 ここまでの整理
適当に書き散らしていて何が言いたいのか自分でもわからなくなった。
- 簡単なソフトウェアを複雑なミドルウェアを利用して構築する。
- これを牛刀式勉強法と言う。
- この勉強法による第一弾の対象をAWSとし、AWS理解のための勉強プロジェクトの名称を炊具一合とする。
5 プロジェクト「炊具一合」始動!
まずは冒頭のウェブサービスを作らねばならない。アプリケーション名は'ITMap(InsTant MAP)'とする。データは24時間以上保持しない。 24時間が経過したデータは自動的に削除されるものとする。今、この瞬間のなんらかの位置情報を誰かと共有する仕組みである。共有し終わったらさっさと忘れてしまうのである。忘れ去られる権利も大事である。
5.1 API仕様
位置情報のアップロードはJSON形式のPOSTメソッドを利用する。 '/itmap/<account>.json'に以下の形式のJSONをPOSTする。
- {
- "password": "sss",
- "comment": "sss",
- "coordinate": [
- {
- "timestamp": 9.9,
- "longitude": 9.9,
- "latitude": 9.9,
- "altitude": 9.9
- },
- {
- "timestamp": 8.8,
- "longitude": 8.8,
- "latitude": 8.8,
- "altitude": 8.8
- }
- ]
- }
5.2 最初の実装
とりあえずさくっとFlask+SQLite3で作る。この組み合わせは個人的にはプロトタイプ作成で最強に近い。
- # main.py
- from flask import Flask
- from flask import request
- from flask import jsonify
- import time
- import sqlite3
- app = Flask(__name__)
- app.config['ITMAP_DB'] = 'itmap.db'
- # Library
- from libs import sqlone
- from libs import sqlany
- from libs import selectone
- from libs import close_conn
- app.teardown_appcontext(close_conn)
- # Routing
- @app.route('/itmap/<account>.json', methods=['GET'])
- def json_get(account):
- sql = """
- SELECT _timestamp,_longitude,_latitude,_altitude
- FROM _coordinate WHERE _name=?
- ORDER BY _timestamp DESC LIMIT 1
- """
- row = selectone(sql, (account,),
- ('timestamp', 'longitude', 'latitude', 'altitude'))
- if row is None:
- return "no acount"
- return jsonify(row), 200
- @app.route('/itmap/<account>.json', methods=['POST'])
- def json_post(account):
- now = time.time()
- sql = "SELECT _update,_password,_comment " +| "FROM _account WHERE _name=? AND _update>?"
- row = selectone(sql, (account, now - 60*60*24),
- ('update', 'password', 'comment'))
- if row is None:
- sql = "SELECT count(*) FROM _account WHERE _update>?"
- row = selectone(sql, (now - 60*60*24,))
- if row is None:
- return "error: no row"
- elif row[0] > 99:
- return "error: too many account"
- # create new account
- sql = "REPLACE INTO _account " +| "(_name,_password,_update,_comment) VALUES (?,?,?,?)"
- sqlone(sql, (account, request.json.get('password'), now, None))
- else: # row is not None
- if now - row['update'] < 60:
- return "error: short interval"
- elif row['password'] is None:
- sql = "UPDATE _account SET _password=?,_update=? WHERE _name=?"
- sqlone(sql, (request.json.get('password'), now, account))
- elif row['password'] != request.json.get('password'):
- return "error: password mismatch"
- else:
- sql = "UPDATE _account SET _update=? WHERE _name=?"
- sqlone(sql, (now, account))
- coordinate = request.json.get('coordinate')
- if len(coordinate) > 5:
- return "error: too many coordinate"
- binds = [(account, row['timestamp'],
- row['longitude'], row['latitude'], row['altitude'])
- for row in coordinate]
- sqlany("INSERT INTO _coordinate VALUES (?,?,?,?,?)", binds)
- return jsonify(request.json), 200
- # Error Handlers
- @app.errorhandler(403) # Forbidden
- @app.errorhandler(404) # Not Found
- @app.errorhandler(500) # Internal Server Error
- def error_handler(e):
- return 'error handler:' + str(e) + ':' + repr(e), e.code
- @app.errorhandler(sqlite3.Error)
- def sqlite3_exception_handler(e):
- return 'sqlite3 exception handler:' + str(e) + ':' + repr(e), 500
- if __name__ == '__main__':
- app.run(debug=True)
main.py
- # libs.py
- from flask import g
- from flask import current_app as app
- # Database
- import sqlite3
- def open_conn():
- dbfile = app.config['ITMAP_DB']
- if '_database_connection' not in g:
- g._database_connection = sqlite3.connect(dbfile)
- g._database_connection.isolation_level = None
- g._database_connection.execute("PRAGMA foreign_keys = ON")
- return g._database_connection
- def close_conn(err = None):
- conn = g.pop('_database_connection', None)
- if conn is not None:
- conn.close()
- def sqlone(sql, bind=()):
- conn = open_conn()
- return conn.execute(sql, bind)
- def sqlany(sql, binds=()):
- conn = open_conn()
- return conn.executemany(sql, binds)
- def selectone(sql, bind=(), field=None):
- cur = sqlone(sql, bind)
- row = cur.fetchone()
- if not row or not field:
- return row
- return dict(zip(field, row))
- def selectany(sql, bind=(), field=None):
- cur = sqlone(sql, bind)
- rows = cur.fetchall()
- if not rows or not field:
- return rows
- return [dict(zip(field, row)) for row in rows]
libs.py
- DROP TABLE IF EXISTS _account;
- CREATE TABLE _account (
- _name TEXT NOT NULL,
- _update REAL NOT NULL,
- _password TEXT,
- _comment TEXT,
- PRIMARY KEY (_name)
- );
- DROP TABLE IF EXISTS _coordinate;
- CREATE TABLE _coordinate (
- _name TEXT NOT NULL,
- _timestamp REAL NOT NULL,
- _longitude REAL NOT NULL,
- _latitude REAL NOT NULL,
- _altitude REAL,
- PRIMARY KEY (_name, _timestamp),
- FOREIGN KEY (_name) REFERENCES _account (_name) ON DELETE CASCADE
- );
itmap.sql
最低限のセキュリティとして、作成できるアカウントは99個までとし、一分以内の連続アップロードは禁止とする。なお、現状、通信路の暗号化を考えていないため、passwordはセキュリティとは関係がない。同じaccountで複数名がPOSTした場合、後のアクセスが優先されるのを(ある程度)防ぐだけである。最初のPOST時にpasswordを設定しておけば、以降、同じpasswordをもたないPOSTは拒否される。すなわち、先のアクセスが優先されるようになる。その他、一度にアップロードできる位置情報は5個までに制限している。
5.3 AWSで動かす
ウェブサービスをAmazonのクラウドで動かさにゃならん。ユーザー登録してEC2インスタンスを作成。さて、ログイン、、、と思ったところで、ユーザIDがわからない。インスタンス作成時にキーペアの作成とキーのダウンロードがあったため、公開鍵を使ったSSHログインだと思われるのだが、初期ユーザってなんだっけ?
'root'で試す。
>>> rootではアクセスできません
そりゃそうだわな。ユーザ登録時のIDでもだめ。ちょっと調べてみると、「ssh -i ... ec2-user@...」でログイン出来るとある。おかしいなぁ、方法は間違えてないはずなのに、、、。で、なんとなく「ec2-user」でログインすると出来ました。おいおい、「ec2-user」は説明のためのサンプルだと思ってましたよ。 EC2では実ユーザとして存在するのね。という訳でEC2インスタンスへのログインは、
- $ ssh -i keyfile.pem [email protected]
ログインできてrootになれれば(sudoが使えるので)何でも出来る。必要な開発環境を構築する。パッケージ管理は、、、「yum」かぁ。 Debian使いの身としては詳しくは知らないが、まぁ、この辺は似たようなものなのでどうにでもなる。 'yum install ...'で、gitとnginxとpython3をインストール。 nginxだけ、なんか専用のコマンドを使えとか言われたのでそうする。で、サービス起動。ブラウザからアクセス。
無反応
うん?おかしいなぁ。サービスは起動している。ポートもちゃんとListenしている。てーことは、なんらかのファイアウォールがあるんだろうな。 Google先生、こんにちは。ほうほう、「セキュリテイグループ」の設定が必要らしい。
ポート開通のために「セキュリテイグループ」のインバウンドルールでファイアウォールに穴を開けろ!
ほいさ。無事、「ITMap」の動作を確認。 EC2上で、超簡単位置情報登録ウェブサービスを提供できたところで第一段階は終了。今後は、炊具一合プロジェクトの趣旨に乗っ取り、あえて、不必要なほどに複雑なAWS各種サービスを利用するように改造。そして、基本機能の拡充である。手始めに、DBをAWSの標準っぽいAmazon Auroraに切り替えてみる。
5.4 一度は見たいオーロラ
本心。
SQLite3ってコンパクトでいいよね。
心の鬼。
大は小を兼ねる!組織化された複雑性は創発を生むのだ!
炊具一合、手始めはSQLite3のAmazon Auroraへのリプレースである。 RDSにも無料枠があるようだ。まずは色々調査から。さぁ、やるぜ!
5.5 見れなかったオーロラ、聖母様お助けください
なんと、、、AuroraとOracleは無料枠の対象外であった。ボッタクリオラクルはわからんでもないが、Aurora、お前もか。 MySQLとPostgreSQLは大昔だけどやったことがある。そうなると、MariaDBだな。これは使ったことがない。 MySQL互換らしいので新鮮味には欠けるかもしれんが仕方がない。
Amazon RDSコンソールからMariaDBのインスタンスを作成。作成方法は簡単作成(標準作成には無料枠がなかった)(間違い)。、、、作成中、、、。結構時間かかるな。カップ麺(5分待ち)が十分に作れる。出来た、接続。Noooooooooo!反応なし。 Google先生、こんにちは。「外部からの接続にはファイアウォールが、、、」またこれか。そもそも、DBを外部からアクセス可能にするにはDBインスタンスにグローバルなIPを振る必要があるみたいだ。これってきっと有料だよね。まぁ、よろしい。内部から(作成済みのEC2インスタンスから)アクセス出来ればそれでいい。 EC2から接続。Noooooooooooo! なんで? AWSのドキュメントを読む。よくわからん。そもそもAWS用語がわからん。 VPC ID、サブネットID、セキュリティグループなどのネットワーキング周りを調査。はぁ、DBインスタンスにもセキュリティグループの設定があるのか。そこにEC2サーバを登録する必要があるようだ。
DBインスタンスの「VPC セキュリティグループ」の設定にて、インバウンドルールの設定でEC2サーバからのアクセスを許可しろ。
5.6 MariaDB用にプログラムを改変
変更部分は殆ど無い。DBへの接続部分を変えるだけ。 Python+MariaDBの開発環境を整えてローカルで検証。 MariaDB用の環境は以下の一文で終わり。
- $ pip install mariadb
- $ pip install mysqlclient
- SELECT * from _account WHERE _name=?
- SELECT * from _account WHERE _name=%s
しかしなぁ、結局やってることは、レンタルサーバとレンタルデータベースで、 PythonとMariaDBを利用したウェブサービスを作っただけなので全然目新しいことをしてる気がしない。
5.7 はじめチョロチョロ、なかパッパ
とりあえず下ごしらえは終わった。データを貯め込む箱は出来たのでパッパと次のステップへ。
1.スマホクライアントを作成する。これは絶対に必要である。スマホから自分の位置をさくっとサーバにアップして、「俺、今、ここにいるんだけど」などと共有すること考えている。ついでに言うと、私はよく山に行くのである。万が一、道迷いなどで遭難してしまった場合、最後にどこにいたかの情報は救助で役立つだろう。
2.Amazon Athena or Amazon Glue などでデータを分析する。過去の位置情報の推移から予想される将来位置を割り出す。頑張れば、イタリアンが好きな(イタリア料理店によく行く)人には、おすすめを紹介するなんてことも出来るだろう。ただし、マーケティングに興味がないのでやる気はない。ところで、私はよく山に行くのである。万が一、道迷いなどで遭難してしまった場合、進路の予想分析が出来れば救助される確率が上がるだろう。
3.Amazon S3 に写真を放り込んで自動でアルバムを作成する。いきなりだが、私はよく山に行くのである。未整理の写真が何千枚とあり、もはや整理する気にもなれない。位置情報と照らし合わせて適切にアルバム化出来るようであれば嬉しい。
とりあえず優先順位をつけずに気が向いたものから少しずつやってみることにする。
5.7.1 S3やってみた
データ分析やるには、データがS3に存在する必要があるみたい。 S3でバケットを作って画像ファイルを投入。さて、何が出来るのやら。 S3 Selectなる項目がある。これがS3内のオブジェクトをSQLで検索できるという機能かな。ファイル形式の選択があって、CSV or JSON or Parquetにしか対応していないようだ。適当なGPSログをCSVに変換してアップロードする。
- select * from s3object s limit 5
- select _1,_2 from s3object s limit 5
5.7.2 Python Script on EC2
なんにも考えずに作成したEC2サーバはアメリカリージョンであった。東京リージョンで作り直して、 PythonからS3にアクセスするのに必要らしいライブラリをインストール。
- $ sudo pip install --upgrade boto3
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- import boto3
- s3 = boto3.client('s3', 'ap-northeast-1')
- response_s3select = s3.select_object_content(
- Bucket = '???',
- Key = '???',
- ExpressionType = 'SQL',
- Expression = 'Select _1,_2 from S3Object s limit 5',
- InputSerialization = {
- 'CompressionType': 'NONE',
- 'CSV' : {
- 'FileHeaderInfo' : 'None',
- 'RecordDelimiter' : '\n',
- 'FieldDelimiter' : ','
- }
- },
- OutputSerialization = {
- 'CSV' : {
- 'RecordDelimiter' : '\n',
- 'FieldDelimiter' : ','
- }
- }
- )
- for event in response_s3select['Payload']:
- if 'Records' in event:
- records = event['Records']['Payload'].decode('utf-8')
- print(records)
- 137.63518,36.246647
- 137.63515,36.246662
- 137.6352,36.246742
- 137.6352,36.24675
- 137.63512,36.246906
少しばかり拍子抜け。てっきり、また、「ファイアウォールが、、、」と来るものだと思ってたよ。むしろ、S3側でアクセス制限解除してないのになぜ繋がるのか不思議。アクセスキーってそういうものなんかな。
RDSからのデータ取得もやってみる。なんにも考えずに作成したRDSサーバはやはりアメリカリージョンであった。東京リージョンで作り直す。ここからプログラムをパクって一部改変。
- import os
- import sys
- import boto3
- import mysql.connector
- ENDPOINT="???.rds.amazonaws.com"
- PORT="3306"
- REGION="ap-northeast-1"
- os.environ['LIBMYSQL_ENABLE_CLEARTEXT_PLUGIN'] = '1'
- #gets the credentials from .aws/credentials
- session = boto3.Session(profile_name='default')
- rds = boto3.client('rds', 'ap-northeast-1')
- token = rds.generate_db_auth_token(
- DBHostname=ENDPOINT, Port=PORT, DBUsername="???", Region=REGION)
- try:
- conn = mysql.connector.connect(
- host=ENDPOINT, port=PORT,
- user="???", passwd=token, database="???")
- cur = conn.cursor()
- cur.execute("""SELECT * from _coordinate limit 5""")
- query_results = cur.fetchall()
- print(query_results)
- except Exception as e:
- print("Database connection failed due to {}".format(e))
RDSへのアクセスはウェブサービスでも利用しているので、普通のパスワード認証はすでに動いている。今回はS3の場合と同様にIAM認証での接続である。ベンダーは囲い込みたがるからね。今後、AWSの他のサービスを利用するにしてもIAM認証は避けて通れないだろうから小手試しである。しかしながら、ここからしばらくは苦難の連続であった。
5.7.3 バイバイ。マリア
うそぉ。RDSでIAM認証に対応しているのは、Aurora、MySQL、PostgreSQLの3つだけであった。ごめんね。マリア。君とはもうお付き合いできない。せっかく東京リージョンで作り直したサーバーをもう一度破棄してMySQLで作り直す。 RDS+IAM認証の手順はここにある。補足として「IAM認証によるRDS接続を試してみた」と「IAM データベースアクセス用の IAM ポリシーの作成と使用」を参考にする。ロールの作成、DBアクセスポリシーの追加、EC2へロールの割当と一通り権限周りを設定して、 DBにIAM認証用のユーザを登録する。先程のスクリプトを実行。エラー。うまく行かないので、コンソールからステップごとに試してみる。
- $ TOKEN="$(aws rds generate-db-auth-token --hostname ???.rds.amazonaws.com --port 3306 --username ??? --region ap-northeast-1)"
- $ mysql -h ???.rds.amazonaws.com --user=??? --password=$TOKEN
- ERROR 1045 (28000): Access denied for user '???'@'???' (using password: NO)
- $ mysql -h ???.rds.amazonaws.com --default-auth=mysql_clear_password --ssl-ca=/home/ec2-user/rds-ca-2019-root.pem --user=??? --password=$TOKEN
5.7.4 [閑話休題] ゼロから作る Deep Learnibg
過学習であった。私の学習は相当効率が悪いし、また、効率が悪くても気にしないのであるが、そもそも、「学習とはなんじゃいな」ということで「ゼロから作るDeep Learnibg」を読んでみる。評価も高いみたいだから、ハズレはしないだろう。半分読む。ニューラルネットワークについては大体わかる。書籍としてハズレではないがアタリでもないと言ったところか。しかし、簡単なことをことさら噛み砕いて説明し、複雑なところは「省略します」や「原論文を参照ください」では、初学者に「理解できた気にさせる」以上にはならないように思われる。特に5章の「誤差逆伝播法」は理解に苦しむ。ここやここを読んだほうが遥かにわかりやすい。それと、バイアスの存在価値がわからない。損失関数が極小値をとる位置を求める問題設定であれば、定数は微分に寄与しないため無駄である。パラメータを増やすという意味でならニューロン数を増やせばよいだけであろう。以下、等式から、
\displaystyle
\left( \begin{array}{cccc}
a_{11} & a_{12} & \ldots & a_{1n}
\\ a_{21} & a_{22} & \ldots & a_{2n}
\\ \vdots & \vdots & \ddots & \vdots
\\ a_{m1} & a_{m2} & \ldots & a_{mn}
\end{array} \right)
\left( \begin{array}{c} x_1 \\ x_2 \\ \vdots \\ x_n \end{array} \right)
+
\left( \begin{array}{c} b_1 \\ b_2 \\ \vdots \\ b_m \end{array} \right)
=
\left( \begin{array}{cccc}
a_{11} & a_{12} & \ldots & a_{1n} & b_1
\\ a_{21} & a_{22} & \ldots & a_{2n} & b_2
\\ \vdots & \vdots & \ddots & \vdots & \vdots
\\ a_{m1} & a_{m2} & \ldots & a_{mn} & b_m
\end{array} \right)
\left( \begin{array}{c} x_1 \\ x_2 \\ \vdots \\ x_n \\ 1 \end{array} \right)
バイアスが必要であったとしても、ウェイト(重み行列)に抱合できるはずと思いながら読んでいたのだが、やはりそれで正しいようだ。書籍記載の参考プログラムからバイアスを取り払って学習させてみたが、認識精度はほぼ変わらないようである。最後まで読めば、アフィン変換の定数項が理論的に意味を持つことになりのだろうか?
5.7.5 [閑話休題] NumPyはクセがすごい、、、というほどでもなかった
NumPyによる計算に戸惑う。一つはブロードキャスト。もう一つは行列演算。数学では列ベクトルも行バクトルもベクトルであり階数は1である。行列に対して列ベクトルは右から、行ベクトルは左からしか掛けることは出来ず、結果は、列ベクトルを掛ければ列ベクトル、行ベクトルを掛ければ行ベクトルとなる。 NumPyでは列ベクトルは(n,1)型の行列、行ベクトルは(1,n)型の行列として表すようだ。(本当は違うのだがネット上の殆どの情報ではそのように説明している。) NumPyのベクトルはどちらからでも掛けることができ、右から掛ければ列ベクトル、左から掛ければ行ベクトルであるかのように振る舞う。(本当は違うのだがネット上の、、、以下略。)そして結果はベクトル(列ベクトルでも行ベクトルでもない)である。
なんだか、変なクセだなぁと思い、三次の行列(テンソル)とベクトルで試してみる。
- >>> x = np.array([1,2])
- >>> A = np.arange(1,9).reshape(2,2,2)
- >>> A
- array([[[1, 2],
- [3, 4]],
- [[5, 6],
- [7, 8]]])
- >>> A@x
- array([[ 5, 11],
- [17, 23]])
- >>> x@A
- array([[ 7, 10],
- [19, 22]])
なるほど、要はテンソルなのである。ドット積は内積ではなく縮約である。 Numpyのndarray型はテンソルである。 (n,)形であれば一階のテンソル(ベクトル)、 (m,n)形であれば二階のテンソル、 (l,m,n)形であれば三階のテンソルである。縮約すればテンソルの階数が下がる。よって、二階テンソル(行列)と一階テンソル(ベクトル)の縮約(ドット積)を取れば、階数が一つ下がって、一階テンソル(ベクトル)となる。 NumPyで言う列ベクトル(や行ベクトル)は、 (n,1)形の二階のテンソルであるから、ドット積は単なる行列同士の掛け算であり階数は下がらない。
先にも挙げた公式文書の記載によると、 NumPyのドット積は、掛ける数、掛けられる数によって5つの場合分けをしている。ある場合は、単なる乗算。また、ある場合は、スカラー積。またまた、ある場合は、内積になったり、縮約になったりと非常に複雑である。ベクトル同士(一階テンソル同士)や行列同士(二階テンソル同士)などの単純な形を除いて、ドット積は縮約であると捉えておいたほうが間違いが少ない。
うーむ。やけに戸惑ったが、これも過学習であろうか。数学の慣用が邪魔をしてるのかもしれない。最後に要点をもう一度。
NumPyのndarray型はテンソルである。
ただし、一階や二階のときは、ベクトルや行列に見せかけるような特殊な演算規則が適用される。
ndarray型をテンソルと考えれば、クセもまぁ、それほどにはすごくないと思える。
5.7.6 はじめまして、アテナさん
趣味に走りすぎた。AWSに戻らねばならない。 Androidアプリも作りたいが、これまた相当に趣味要素が強くなりそうなので後回し。データを貯め込む箱は出来ている。テスト用のデータも沢山ある。そして、データがあるなら分析である。 AWSの分析サービスによると、インタラクティブ分析がAmazon Athenaで、リストの最上位にあるのでこれから始めてみることにする。さぁ、マリアと別れて、アテナである。「はじめまして、アテナさん。しばらくお付き合いくださいませ。」「はじめまして。私も処女です。」なにやら身持ちが硬そうである。
何はともあれデータ取得が出来なければならない。 Athenaのコンソールから、データベースとテーブルを作る。手順はこちら。尊師グルに頼めば、データソースをクローリングして自動スキーマ生成ができるようであるが、いきなり頼るのは良くないのでスキーマを自作する。最初に「Settengs」の「Query result location」を設定する必要があるらしいが、何を入力してよいのかわからないので適当な文字列で埋めておく。 [Query Editor]から「CREATE DATABASE ...」や「CREATE TABLE ...」コマンドで、データベーススキーマとテーブルを作成できたが、テーブルに関しては作成ウィザードがあるのでそれも利用してみる。左サイドバーの「Create Table」から「from S3 bucket data」を選んで必要項目を入力すれば、テーブルが作成される、、、という訳ではなく、テーブル作成のDDLが[Query Editor]に生成される。
テーブルが出来たところでインサートしてセレクト、、、は出来ない。スキーマを作成してもまだ実際のデータ(S3上のファイル)とは紐付いていない。実データとの紐付け無しでテーブルが作成できてしまったことの方がむしろ驚きであった。 Settingsはいい加減だし、適当な名前で作成したテーブルでS3からデータ取得できればもはや魔法である。ドキュメント嫌いなので試行錯誤。(実際、ドキュメントっていい加減なことが多いし。)以下の設定でS3上のCSVファイルからSQLでデータを取ることが出来るようになる。
- 「Settengs」の「Query result location」は「s3://バケット名/フォルダ名/」を設定する。このフォルダは事前にS3で作成しておく。ここにAthenaが発行したクエリのログが格納される。
- 作成するテーブルの名前はS3上のファイル名(拡張子を除く)に合わせる。ファイル名が「foobar.csv」であれば、テーブル名は「foobar」である。
お次はスキーマ自動生成である。 Google先生にお願いして、二日前に公開されたばかりの動画を紹介してもらう。
注)ファイル名とテーブル名を合わせる必要ないかもしれない。
フォルダ以下のファイルは全て結合されるようである。
ファイルとDBスキーマの結合構文はHive DDLらしいので、そちらを勉強すべし。
本文記載のように、ウィザードによるテーブル作成はHive DDLの生成である。
5.7.7 尊師グルのスティッキー・フィンガーズ!
動画視聴中。ふむふむ、なるほど。なんて丁寧な解説なんだ。動画の前半はRDSのデータベースのスナップショットをS3に放り込む方法。後半がAmazon Glueでの自動データベーススキーマの生成とAthenaによるデータ分析(取得)。動画の手順通りに、
- 新しいS3バケットの作成
- 適当なCSVファイルをバケットに放り込む
- Amazon Glueでクローリングを設定して実行。
- Amazon Athenaにデータベースが作成されている!
Glueでのスキーマ生成では、CSVファイルの先頭行は正しくカラム名として扱われる。
ただし、全ての列が文字列タイプである場合、
正しく先頭行を分離できないので'col0'みたいなカラム名になる。
JSONやParquetは要調査であるが、
データ形式からして正しいカラム名が自動付与されると思われる。
前章、注のように同じフォルダ配下のファイルはテーブルとしてJOINされる。
よって、フォルダ名=テーブル名となるようにS3にデータファイルを配置するのが良さそう。
AmazonがAWSで考えるデータレイクとはS3そのもののようである。とりあえず、何でもかんでもS3に放り込んで、尊師グルにデータベーススキーマを作成してもらう。グルと言えどもそれなりに間違うので、手動でスキーマを訂正して、後は「SQLで自由に分析してください」と言うことだろう。 RDLはスナップショットをS3にエクスポートすればよい。分析にリアルタイムデータが必要になることはまずなく、ある時点でのデータに対する分析となるだろうからこれは理にかなっている。どうしてもリアルタイム分析がしたければ直接RDLを叩けば良い。分析の為のデータ取得はどのみちSQLだ。データベース横断(データソースがS3とRDLに分かれていても)の SQLによるテーブル結合も可能かもしれない(まだやってはいない)。
5.7.8 ラムだっちゃ!
マリア、アテナ、そして尊師グルとまでお付き合いするダーリンが、節操なく次に手を出すのはLambdaである。 AWSのデータ分析の要はS3のようなので(RDSもスナップショットを取ってS3にぶっ込めなので)、 S3用のチュートリアル「アップロードした画像ファイルのサムネイル画像を自動的に生成する」にチャレンジしてみる。非常に浅い理解だが、Lambdaとは掻い摘んで言ってしまえばただのウェブサービスである。 AWSの構成要素(例えばS3)の何らかのイベント(例えばファイルが更新された)がトリガーとなり、 JSON形式のメッセージがウェブサービスであるLambdaの関数に渡される。 Lambdaの関数は受け取ったメッセージを処理し、変換されたメッセージを次のサービスに回送する。ウェブサービスとして実装したフィルタのようなものと理解して良さそうである。前述チュートリアルでは、
- S3にファイルが作成される。
- ファイル作成イベントをトリガーとしてLambda関数にメッセージが送出される。
- Lambda関数は作成されたファイル名などの情報をメッセージから受け取りサムネイル画像を生成する。
チュートリアル自体はそのままで問題なく実行できた。サンプルがnode.jsだったので、その環境構築の方が時間がかかったくらい。 EC2上のNode.js環境構築はこちらやこちらを参照。また、途中デプロイパッケージの作成でC++のコンパイルが必要になるようなので、「sudo yum install gcc-c++」でコンパイラをインストールしておく。また、awsコマンドによる関数の作成では、 EC2側にもLambdaに関する権限が必要であったので、とりあえず「AWSLambdaExecute」と「AWSLambdaFullAccess」を付けるとうまく行った。覚書としてはこのくらい。 node.jsはやったことがないので、とりあえずわからないまま手順通りに実施したが問題なし。次はこれのPython実装を試してみようと思う。 Lambda、及び、AWS各種サービスのAPIは全貌を理解するのに時間がかかりそうだ。しばらく浮気はしない予定。
5.7.9 モンティだっちゃ!
サクっとPython化。こちらも手順とプログラムのサンプルがある。勝手知ったるお友達のPythonだし、余裕だろうと高をくくっていたら少々手こずった。結論から言うと、動かすためのプログラムと手順は以下の通り。
- import io
- import json
- import boto3
- import os
- import sys
- import uuid
- from urllib.parse import unquote_plus
- from PIL import Image
- import PIL.Image
- s3_client = boto3.client('s3')
- def resize_image(image_path, resized_path):
- with Image.open(image_path) as image:
- image.thumbnail(tuple(x / 2 for x in image.size))
- #image.save(resized_path)
- image.save(resized_path, 'JPEG')
- def lambda_handler(event, context):
- for record in event['Records']:
- #return { 'statusCode':200, 'body':json.dumps(record) }
- bucket = record['s3']['bucket']['name']
- key = unquote_plus(record['s3']['object']['key'])
- #tmpkey = key.replace('/', '')
- #download_path = '/tmp/{}{}'.format(uuid.uuid4(), tmpkey)
- #upload_path = '/tmp/resized-{}'.format(tmpkey)
- #s3_client.download_file(bucket, key, download_path)
- #resize_image(download_path, upload_path)
- #s3_client.upload_file(upload_path, '{}-resized'.format(bucket), key)
- orig = io.BytesIO()
- s3_client.download_fileobj(bucket, key, orig)
- orig.seek(0)
- #return { 'statusCode':200, 'body':len(orig.getvalue()) }
- nail = io.BytesIO()
- resize_image(orig, nail)
- nail.seek(0)
- #return { 'statusCode':200, 'body':len(nail.getvalue()) }
- s3_client.upload_fileobj(nail, '{}-resized'.format(bucket), key)
lambda_function.py
- $ python3 -m venv v-env (多分、'virtualenv -p python3.7 v-env'でもよい。)
- $ source v-env/bin/activate
- $ pip install Pillow boto3
- $ cd $VIRTUAL_ENV/lib/python3.7/site-packages
- $ zip -r9 ${OLDPWD}/function.zip .
- $ cd ${OLDPWD}
- $ zip -g function.zip lambda_function.py
- $ deactivate
packaging
- $ aws lambda create-function --function-name CreateThumbnail2 --zip-file fileb://function.zip --handler lambda_function.lambda_handler --runtime python3.7 --timeout 10 --memory-size 1024 --role arn:aws:iam::????????????:role/lambda-s3-role
deploy
- $ aws lambda invoke --function-name CreateThumbnail2 --invocation-type Event --payload file://inputFile2.txt outputfile.txt
test
プログラムにはデバッグ過程を追うためのコードをコメントアウトで残してある。まず、サンプルはPython3.8用だが、EC2の標準パッケージではPython3.7であったため、バージョン指定を変えている。デプロイについての'--handler'と'--runtime'のオプション指定はこことここを参考にした。
以下、経緯を少し。まずは、サンプルのままのプログラムで実行、エラーなし。しばし待ってS3にアクセスするもサムネイル画像が作成されていない。ログを確認するも'No Error'だそうな。これ、一番困る奴や。しれっと正常終了してログも吐かずに動作だけしていない。 AWSに限らんのかもしれんけど、デバッグしにくいなぁ。プログラムのバグか、設定ミスか、環境まわりの整備が悪いのか全くわからない。仮想環境をvirtualenvからPython3標準のvenvに変えたりしてみたが駄目。サンプル手順はPython3.8で説明されているが、EC2でインストールされるPythonのバージョンは3.7である。 Pythonのバージョンアップはしたくない(パケージ管理されなくなるから)。まぁ、こういう問題状況でこそ消防士としての手腕が試されるときだ。環境周りでの問題とは考えにくいので、おそらくサンプルプログラムのバグであろうと読んでみると、明らかにテンポラリファイルの作成処理に疑問を感じる。 Lambdaってサーバーレスだよね。フォルダ'/tmp/...'指定して一時ファイルを作るっておかしくないか?そのフォルダは一体どこのサーバーにあるんだよ。で、すべてオンメモリで処理するように変更したら動作しました。うーん。なんで一時ファイルが作成されない時点でエラーになってくれないのであろうか?ヘビ毒って激痛なんだよ。噛み付いといてなんの症状もなしとかヤメてほしいわ。一時間で終わる予定が三時間はかかっちゃたよ。テストが面倒であった。
5.7.10 Androidで位置情報の送信
本節はObsoleteです。独立したページを作成したのでこちらを参照のこと。
GPSログをとるための野良アプリを開発。これとこれとこれの 3つを読めば作成できる。その他、公式ドキュメントも適当に拾い読みして知識を補う。ソースはそこそこ長くなるのでGitHubにて公開する。マイデバイスはAndroid10のみなので、他バージョンでのコンパイル、及び、実行可能性は不明(というか興味なし)。
プレイストアで探せば、優秀なGPSロガーはいくらでもある。そんな中、わざわざ新たに似たようなアプリを作るのは暇だから勉強のためである。それに、ItMap(自作アプリの名前)はそんじょそこらの凡百GPSロガーとは持ってる機能が桁外れだ。そう、ほとんど機能がない。ほぼ何もできないと言ってよいクズアプリであろう。唯一の利点は記録データをリアルタイムでサーバにアップロードできることである。以下、使用法のメモ。
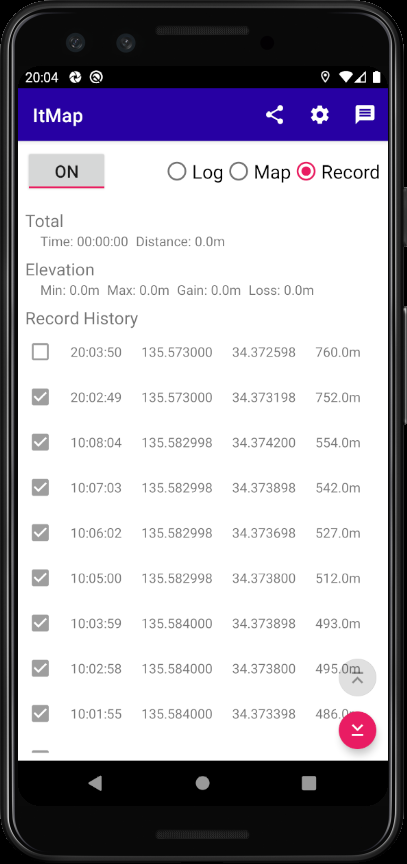
- Share (現在地の地図を表示するURLを他アプリと共有する)
- Setting (各種設定ダイアログ、位置情報の記録間隔やアップロード頻度など)
- Message (メッセージを設定するダイアログ)
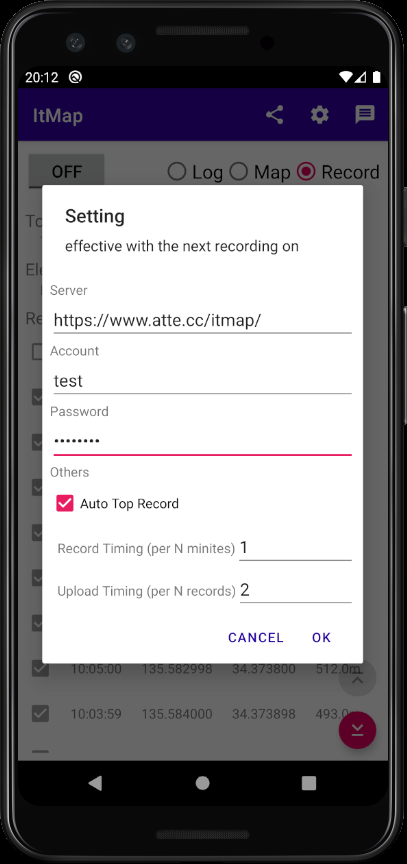
- Server:位置情報をアップロードするサーバのURL。API仕様はソース(ItMapApiService.kt)読め
- Account:アップロードする際のアカウント。位置情報はアカウント毎に記録される
- Password:アップロードで必要になるパスワード
- Auto Top Record:チェックすると自動で最上部までスクロールされる
- Record Timing:何分毎に位置情報を記録するか
- Upload Timing:何回位置情報を記録する度にアップロードするか
5.7.11 Androidで位置情報の記録
余計なアップロード機能なんていらない。記録だけできれば良いということもあるので更に機能限定版。世にあるGPSロガーを使った方が便利だと思うけど、 Android10におけるリファレンス実装になればいいかなと思ってこちらも公開。本当にシンプル。記録してるだけ。保存も面倒だったので共有で済ませた。 Google Driveとか適当なFile Managerとかと共有すれば保存はできる。あと、アプリの設定から手動で「位置情報権限」を追加する必要有。記録開始時に権限がなければ通知が出るので、その通知をタップすれば設定画面が開きます。これも権限承認の実装が面倒だったがゆえの手抜き(簡単だが長くなるのでプログラムがきたなくなる)。